
- 27th Feb 2024
- 06:03 am
Knowledge of customer behaviour is of paramount importance to any business today. There is so much information out there and the businesses have to come up with ways of making sense out of it. A good approach would be that of unsupervised learning, and the latter can be assistive in discovering patterns within the data without using labels or already defined categories. In the following blog, we will go through the process of how this kind of machine learning can be applied to segment customers into meaningful segments. We'll also cover common techniques and how businesses apply them in the real world.
What is Unsupervised Learning?
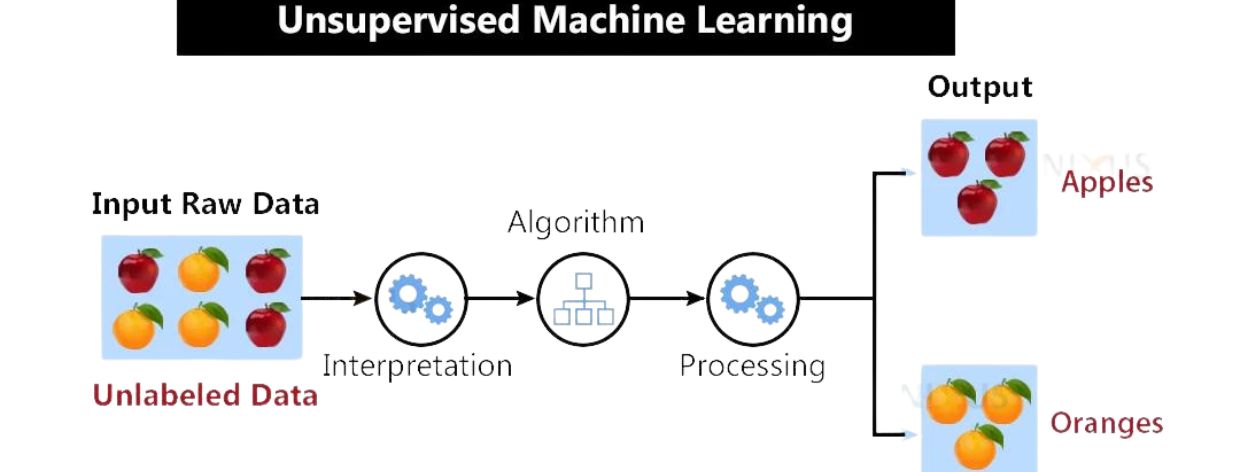
Unsupervised learning In machine learning, this refers to a system that seeks to discover inherent patterns in unlabeled data. In contrast to supervised learning where the known outcomes are required, unsupervised learning does not specify any of the target values. It merely analyzes information and attempts to unlocate covert structures. One such scenario is customer segmentation, where customers are assigned to categories, depending upon their common notable similarities or patterns, such as the frequency of purchases or purchased products.
Why Does Customer Segmentation Matter?
Breaking your customers into smaller groups helps you understand them better. This allows businesses to:
- Create targeted marketing campaigns
- Recommend products more accurately
- Improve customer satisfaction
In the example, knowing which group likes products at a low price vs products at high prices then you can market the right products to the right group. This may eventually give rise to a more loyal customer base with improved sales performance.
Common Methods to Segment Customers
It could be compared to grouping people in a place according to their interests; sports enthusiasts in one location, music fans in another. Similarly, companies employ clustering algorithms to segregate customers having similar habits.
Here are a few common techniques:
-
K-Means Clustering
Probably the simplest and most popular of cluster methods is called k-means. You begin by selecting the number of groups (or clusters) desired. Then the algorithm will assign each customer to the closest cluster optimally according to their data and will go on adjusting until all fits well.
It is fast and works well with large datasets. However, the disadvantage is that you have to determine the number of groups in advance, which can be difficult if you are not safe.
-
Hierarchical Clustering
Unlike K-means, this method does not require that you determine the number of clusters in the beginning. It begins with each data point as its own cluster and continues to beat them step by step based on their similarities.
The result is a three -like structure (called a dendrogram) that shows how the clusters are related. This is a good method when you require getting to know your data in a more free way and appreciate how it naturally clusters.
-
DBSCAN (Density-Based Clustering)
DBSCAN works differently. Instead of focusing on distances or deciding cluster numbers in advance, it groups together points that are close to each other and marks points that don’t fit in any group as “noise.”
It’s especially useful when dealing with data that forms clusters of different shapes and sizes. Also, since it doesn’t assume a specific structure, it can handle messy or irregular data quite well.
How Businesses Use Customer Segmentation
The following are some of the ways through which company make use of customer segmentation:
- It is utilized on online retailers to recommend products, provide discounts and better pricing strategies.
- Bricks-and-mortar shops utilize it to stock their shelves with other appropriate items and look out for their most common customers.
- Banks also employ segmentation as a strategy of identifying suspicious transactions, measuring loan risk, and enhancing customer services.
These are some of the opportunities to explain why it might be helpful to get to know your customers more and differentiate them according to their preferences.
Tips for Doing It Right
In case you intend to apply unsupervised learning to customer segmentation, these are several aspects you will want to consider:
- Clean your data first. Fix errors and fill in missing values before running any algorithms.
- Pick the right features. Only include data points that really matter—like purchase frequency or location.
- Measure your results. Use evaluation tools to see whether your clusters actually make sense.
- Make it understandable. The segments you find should be easy to explain and use in business decisions.
- Keep improving. Try different techniques, fine-tune the settings, and revisit the data over time.
Conclusion
Unsupervised learning plays a crucial role in helping companies to master the art of customer segmentation and help companies make data-based decisions and approach customers in a personalized way. It does not matter whether you are analyzing K-means, hierarchical clustering, or DBSCAN since an insight into these techniques would uncover significant patterns in the behavior of your customers. In case you want to search expert guidance, then our SPSS Assignment Help, Machine Learning Assignment Help, Data Analytics Assignment Help, STATA Assignment Help and Econometrics Assignment Help services are here to assist you. Our professionals will make your learning process easy and will guide you to achieve your academic or project purposes successfully.
About The Author:
- Name: Sarah Johnson
- Qualification: Master's in Data Science
- Bachelor's Degree: Bachelor of Science in Computer Science
- Master's Degree: Master of Science in Data Analytics
- Research Focus: Application of unsupervised learning in customer segmentation
- Expertise: Experienced in K-means, hierarchical clustering, and DBSCAN for clustering analysis.







