
- 29th Feb 2024
- 06:03 am
Named Entity Recognition (NER) is a critical application in natural language processing (NLP) that aims at detection and the classification of things like names of people, organizations, places, dates, and others in unstructured text. It is crucial to various NLP tasks, which is why students and professionals should feel knowledgeable about them and be able to solve NER tasks. The entire guide will ease the main ideas of NER at the same time describing the main techniques and approaches that are required to excel in similar activities.
Understanding Named Entity Recognition
Named Entity Recognition (NER) is the process of identifying and classifying text entities into predetermined classes including the name of persons, organizations, location names, etc. It commonly carries out the task by using machine learning or deep learning models that have been trained on labeled datasets to automatically find and classify these entities in unstructured text.
Methodologies for Named Entity Recognition
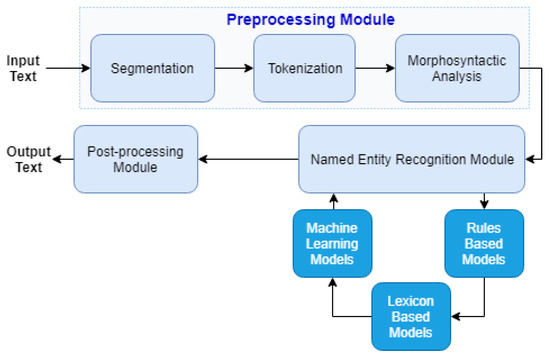
- Rule-Based Approach: The procedure entails the formation of a list of predetermined rules or patterns which are used to detect units on the basis of the grammar and sentence structure Although easy to understand and implement, it can struggle with flexibility and complex device formats.
- Machine Learning Approach: This approach uses monitored learning algorithms as conditional random fields (CRF) or support vocal machines (SVM), trained on tagged data to automatically detect and classify devices.
- Deep Learning Approach: Advanced neural networks such as RNNs, LSTMS and transformer-based models such as Bert are used in this method. These models are very effective at understanding context and have achieved excellent results in unit recognition tasks.
Strategies for Solving NER Assignments
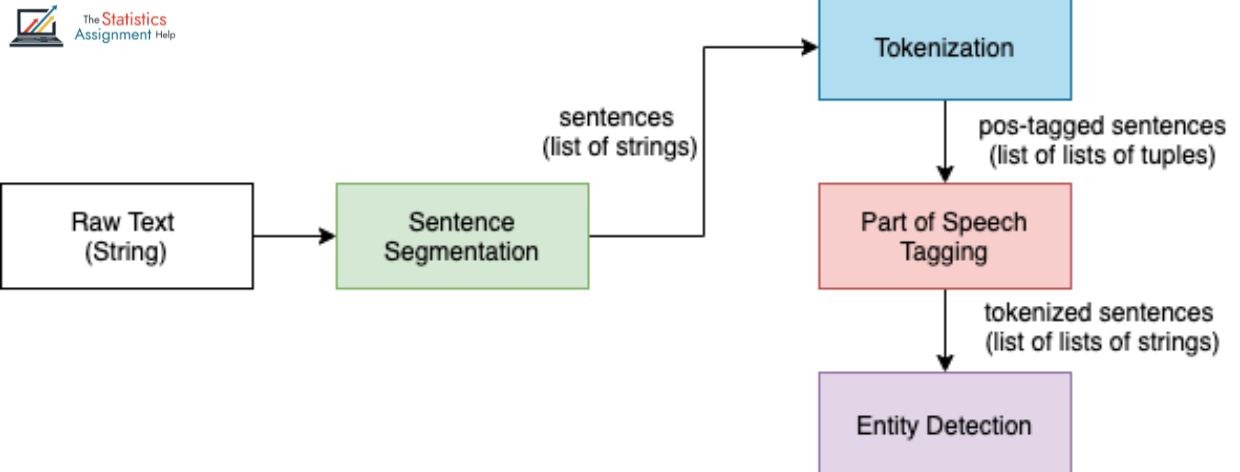
- Data Preprocessing: Start by cleaning the text to remove noise, divide it into single words or expressions (tokenization) and normalize the text for consistency. This step helps you ensure that the named Unit Recognition (NER) model receives clean, standardized input for better results.
- Feature Engineering: Extract features using the text, i.e. embedding, part-of-speech tags and syntactic patterns. These functions assist to formulate the sense and boundaries of the text, and to enhance the model capacity to recognize the devices in an accurate manner.
- Model Selection: Select the right machine learning or deep learning algorithm based on the complexity of tasks, amount of data available and the access to the computing power. Adequate selection of a model guarantees higher precision and use of resources.
- Training and Evaluation: Train the selected model using labeled data and evaluate performance using key measurements such as precision, recalling, F1 points and accuracy. This helps to confirm the model's ability to identify and classify devices correctly in the text.
- Fine-Tuning and Optimization: Optimize the parameters of the model, tune the hyperparameters and research methods like ensemble learning to gain additional performance. These enhancements assist to enhance the quality and precision of the NER outcomes.
Challenges and Solutions in NER Assignments
- Data Sparsity: Inadequate annotations of some entities or domains may decrease model quality. Such cases can be improved with techniques such as data augmentation, transfer learning, and domain adaptation.
- Ambiguity and Noise: There is a distraction with ambiguous words and noisy text. This is handled by excellent preprocessing, meaningful features and situation-sensitive models.
- Out-of-Vocabulary Entities: Entities not seen during training are hard to detect. Character-level embeddings and external knowledge sources can improve recognition of such entities.
- Named Entity Linking: Linking identified entities to knowledge bases is complex. Disambiguation methods and linking algorithms help match them with the correct references.
Real-World Applications of Named Entity Recognition
- Information Extraction: This involves transforming unstructured text into structured formats such as the application of Named Entity Recognition and parsing text. These approaches enable to establish the key entities and their interactions, therefore, enabling to apply data in different tasks, e.g. sentiment analysis and information retrieval.
- Question Answering Systems: Systems that provide precise responses detect significant entities in a user query first. This assists in retrieving most relevant information in databases or documents.
- Entity-based Search: Identifying both queries and documents entities is what delivers search engines more reliable and pertinent results. It improves search results to be more in line with user intent.
- Chatbots and Virtual Assistants: These systems employ entity recognition to interpret important information in text messages by users. This enables them to be more precise and personal in responding to the users thus enhanced interaction and communication effectiveness.
Conclusion
Named Entity Recognition (NER) is an essential concept of natural language processing and is used in a large number of industries. In order to be able to get a good performance in NER tasks, the domain should be known well, it is necessary to clean and preprocess the data, select features, select models, and tune them to obtain better outcomes. Students and professionals can better develop NER skills and make a difference by studying the relevant methods and approaches taught in this guide. Trying to find information and working on NER projects and feel lost? Our Machine Learning Assignment Help service will help you get the necessary information with the help of experts.
About The Author:
- Name: Dr. Emily L.
- Qualification: Ph.D. in Natural Language Processing
- Expertise: Dr. Emily L. is a leading NLP expert with a focus on Named Entity Recognition (NER). Her research has made notable contributions to advancing text analysis.
- Research Focus: Dr. L. develops advanced NER methods, focusing on improving accuracy and efficiency through innovative algorithms.







