
- 27th Feb 2024
- 06:03 am
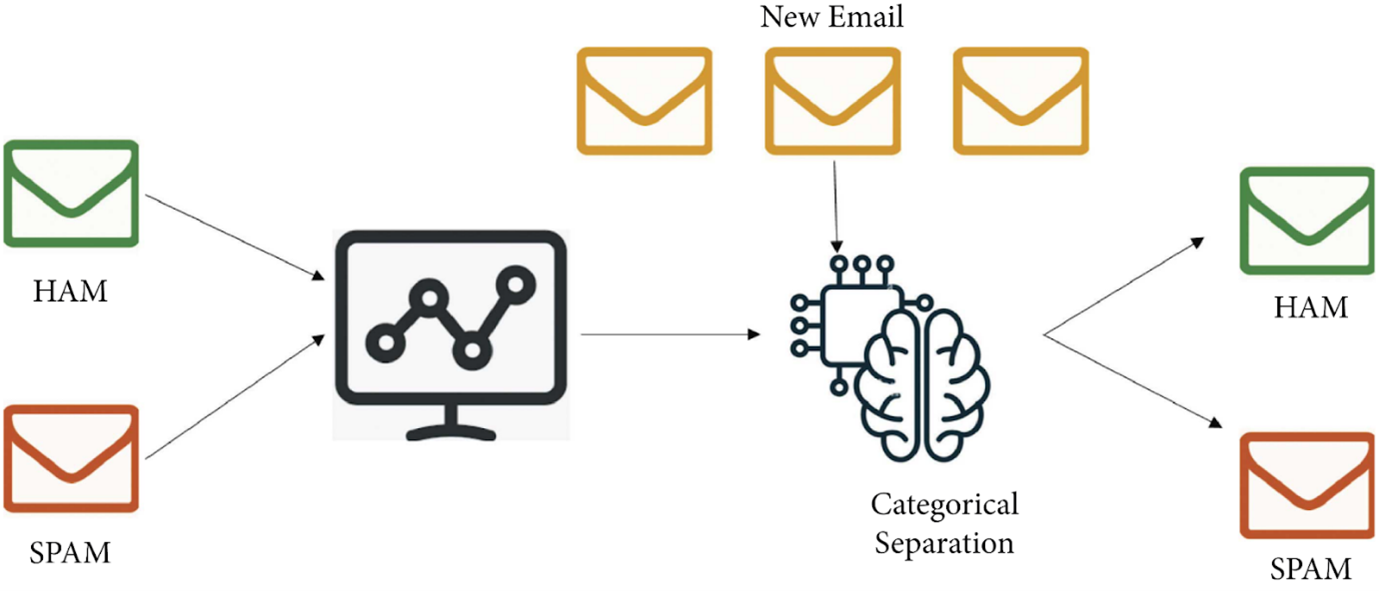
Email is a key tool for communication in our daily lives. Unfortunately, with the convenience of email comes the constant flood of spam, which can be both annoying and dangerous. To filter out this digital clutter, many rely on intelligent systems. One of the most powerful methods for detecting spam is Supervised Machine Learning (SML). By training models on labeled examples of spam and non-spam emails, SML can effectively differentiate between unwanted and legitimate messages. In this blog, we break down how SML works for email classification in a simple, step-by-step format.
Understanding Supervised Machine Learning
Supervised Machine Learning is a fundamental idea or concept of artificial intelligence in which an algorithm uses labeled data to learn. Every training data does have an input feature and a known output (label) and with this, the pattern is discovered by the algorithm. With time it modifies its internal parameters to fold in more predictive capabilities and enhance its effectiveness.
This method is widely used across industries - from spam detection and sentiment analysis to health diagnostics and autonomous systems. Gripping SMP involves understanding model training, data functions and performance evaluation, which enables the development of reliable predictive systems.
Preprocessing The Email Data
Before diving into model training, preprocessing the email data is crucial to extract relevant features and ensure optimal performance. This involves several steps:
- Text Cleaning: First, we split the email text into smaller parts called tokens, which are usually words or phrases. This helps the computer understand the text better.
- Tokenization: Then, we break down the text into individual words or tokens.
- Normalization: Then, we change all the text to lowercase to keep everything uniform.
- Stopword Removal: Then, we eliminate such common words as and or the since they simply do not describe the meaning of this email.
- Stemming or Lemmatization: Finally, we simplify words by reducing them to their root form. For example, we change "running" to "run" to make things simpler for the computer.
Feature Extraction
Feature extraction means turning the cleaned-up text into numbers that the computer can work with. Some common ways to do this include:
- Bag-of-Words (BoW): We represent each email as a bunch of numbers, sort of like coordinates on a graph. Each number stands for a different word in all the emails combined. The value of each number tells us how many times that word shows up in the email.
- Term Frequency-Inverse Document Frequency (TF-IDF): Give every word in the email a prominence by looking at each of them with the frequency of occurrence not only within the email, but across all the emails. This aids in determining which words are of significance all through the emails and not only in one of them.
Model Selection and Training
Now that we've cleaned up the data and turned it into numbers, the next step is picking the right computer program to help us sort the emails. Some popular choices for this are:
- Naive Bayes: The algorithm is a simple (though rather effective) use of the Bayes theorem to classify text into various categories.
- Support Vector Machines (SVM): SVMs (Support Vector Machines) are actually very good at making clear-cut boundaries between various groups, particularly when there are a great many different things to be taken into account (such as in text). This is the reason why they are frequently employed in classifying text into various categories.
- Random Forest: A flexible ensemble learning method, which combines many decision trees in order to improve the overall performance of the forest.
The selected algorithm is trained on the labeled dataset, as a result of which the model will learn to differentiate between spam and non-spam messages using the features that it extracts.
Model Evaluation and Fine-Tuning
To see how our model is performing after training, we examine its performance on some other set of emails with different measures such as: accuracy, precision, recall, and F1-score. We also apply techniques such as cross-validation to determine the extent to which the model will be able to deal with new situations.
Fine-tuning involves getting the settings right and enhancing the functions of the model so as to make it any better. We do this by tweaking things like hyperparameters and the model's design. This helps find the right balance between making the model too simple or too complicated, so it can accurately sort new emails.
Deployment and Integration
Once a supervised machine learning model shows reliable performance, it’s deployed into real-world systems for live email filtering. Integration links the model to email boards and makes incoming messages be automatically classified. The model can learn new spam strategies, because it can be constantly monitored and augmented with new labeled data. Notably, the appropriate implementation and integration have also increased email security and cybersecurity.
Continuous Monitoring and Adaptation
Spam strategies are continually evolving and it is optimally necessary to check and update email classification systems frequently. Regular adjustments based on new information and understandings of new dangers aid the model to remain efficient in the detection of spam. This ongoing analysis further makes the system more precise and resilient with reliability of protection in the continuously surging ocean of unwanted emails.
Leveraging Supervised Machine Learning for Email Classification
Supervised Machine Learning as a spam detection strategy provides an automated and effective way in filtering email. The students providing the learning of this issue will be able to gain direct experience in conducting such methods as tokenization, feature extraction, and model tuning. To struggling students, professional assistance with Supervised Machine Learning homework may provide a much-needed clear explanation and practical knowledge of what it takes to create spam filters and other related programs.
Conclusion
Supervised Machine Learning presents a very effective approach to finding spam emails in a precise way. They can enhance cybersecurity and facilitate the simplification of digital communication with the help of such models after learning on labeled data and adjusting to emerging tasks. Gain a new sense of discovery in classification of email and as a student or professional, help your career with our effort to explain and demonstrate SML techniques. When you require assistance to develop such projects or learn these concepts, then review our Machine Learning Assignment Help to enhance your learning process.
About the Author:
Name: Dr. Sen R
Qualification: Ph.D. in Computer Science
Bachelor's Degree: Computer Science
Master's Degree: Specialization in Machine Learning Algorithms
Research Focus: Application of Supervised Learning Techniques in Email Classification
Expertise: Data Science, Artificial Intelligence







